
In the age of data-driven decision-making, selecting the appropriate data storage solution is highly crucial for businesses. Although two prominent options, Data lakes and Data warehouse may sound similar, but they offer distinct approaches to data management. However, like any important choice, such as data lake vs data warehouse, it involves careful considerations.
As I was saying, a data lake is a storage repository that holds all of an organization’s data, whether structured or unstructured. On the other hand, a data warehouse contains only structured historical data processed for specific purposes. So, depending on requirements – understanding such storage techniques become crucial for building a robust data storage pipeline for businesses.
Therefore, this blog will compare the two options and help you to choose the best next-gen data management solution. (If you want to save time and book a ree consultation call to explore more, here we are)
What is a Data Lake?
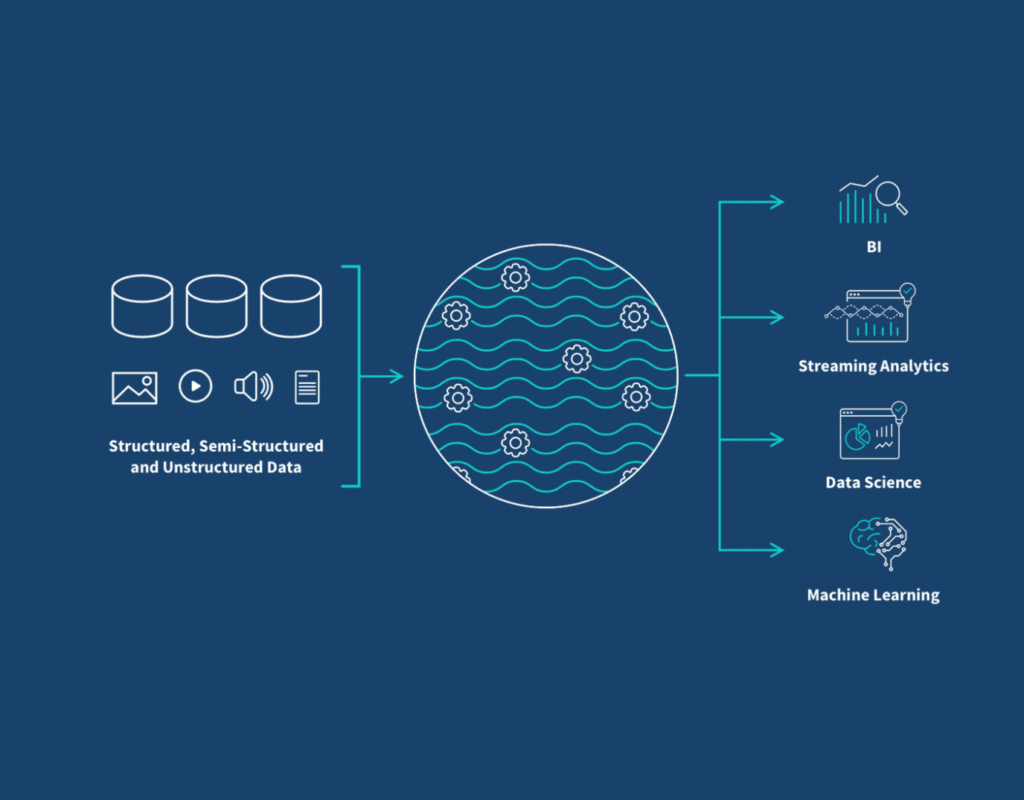
As you may already know, a data lake is a centralized repository allowing businesses to store all structured and unstructured data at any scale. Likewise, companies can store their data as it is, without having to first structure it. In addition, they can run different types of analytics from dashboards and visualizations to big data processing.
Furthermore, it leverages real-time analytics, and machine learning in order to guide business leaders like yourself, to make better decisions.
Characteristics of Data Lakes
Now, here are some of the key characteristics of data lakes:
Schema-on-Read
To begin with, a schema is applied when the data is read or analyzed, offering flexibility in how the data can be utilized.
Accordingly, data lakes employ a schema-on-read approach, meaning that data is stored in its raw form without a predefined schema. Plus, this approach allows for the storage of diverse data types and the ability to handle evolving data requirements.
Storage of Data
One of the primary advantages of a data lake is its ability to store various types of data:
- Raw Data: Data is ingested in its original format without any transformation.
- Unstructured Data: It includes text files, images, videos, and other multimedia content.
- Semi-Structured Data: Additionally, it also includes JSON, XML, and CSV files that have some organizational properties.
- Structured Data: Also, traditional data formats such as tables and databases with a defined schema can be stored as well.
As a result, this versatility makes data lakes suitable for a wide range of data storage needs.
Scalability and Flexibility
It is designed to scale horizontally, accommodating petabytes of data without significant changes to the infrastructure. Besides, this is achieved through distributed storage and processing frameworks, enabling businesses to expand their data storage capabilities seamlessly. Moreover, the flexibility of data lakes allows them to support a wide range of web-application frameworks, like:
Use Cases of Data Lakes
Now, in accordance with our debate between data lake vs data warehouse – It is necessary to understand their specific use cases in order to leverage them efficiently.
Likewise, in this section we will see how data lakes showcases its advantages:-
Big Data Analytics

A primary use case for data lakes, as they provide the necessary infrastructure to store, and manage diverse data. Subsequently, this capability is crucial for businesses to gain insights from their data to drive strategic decisions.
With that said, here are some specific ways data lakes are used for big data analytics:
- Handling Large Volumes of Data: Data lakes are designed to handle petabytes of data, allowing organizations to ingest and store data from multiple sources. Consequently, it ensures that businesses can maintain comprehensive datasets that reflect all aspects of their operations.
- Data Ingestion and Integration: It supports the ingestion and integration of data from multiple sources, both in batch and real-time. Moreover, this capability allows businesses to consolidate data into a single repository, making it easier to perform comprehensive analyses.
- Enhanced Data Exploration: The schema-on-read approach used by data lakes allows analysts to explore data without the constraints of predefined schemas. Also, it enables ad-hoc querying and data exploration, allowing businesses to discover new patterns, correlations, and insights.
- Real-Time Analytics: Additionally, it can process and analyze streaming data in real-time, enabling businesses to gain immediate insights and make timely decisions. Also, it is valuable in scenarios where rapid response is crucial, such as fraud detection, network monitoring, and dynamic pricing.
Overall, big data analytics offers an extensively powerful and adaptable solution. It functions as a massive storage facility, empowering businesses to retain, manage, and analyze vast quantities of information.
Machine Learning and AI

Data lakes support Machine Learning and AI initiatives by managing and analyzing large volumes of diverse data for advanced insights. In essence, here’s how data lakes facilitate ML and AI applications:
- Centralized Data Repository: It offers a centralized repository where businesses can store raw and diverse datasets. Consequently, this centralization is a key feature, as it allows data scientists to access comprehensive datasets and feed them to AI-systems.
- Data Preprocessing and Feature Engineering Before training ML models, data often requires preprocessing and feature engineering. Likewise, data lakes allow this by storing data in its raw form, allowing data scientists to perform necessary transformations. In addition, tools and frameworks integrated with data lakes, like Apache Spark or Databricks, facilitate these processes efficiently .
- Model Training and Experimentation With access to large and diverse datasets, data lakes support extensive model training and experimentation. Data scientists can test various algorithms, tune hyperparameters, and validate models using the comprehensive data stored in the lake. Furthermore, this iterative process helps in developing more accurate and robust ML models.
- Advanced AI Models and Analytics: Data lakes support advanced AI analytics techniques and models, including deep learning, natural language processing (NLP), and computer vision. By storing a wide variety of data types, it allows for the development of sophisticated AI applications, like – Image Recognition, Sentiment Analysis, and Conversational agents.
In addition, it is advised for businesses with an objective of leveraging such robust AI analytical models – to check out our guide on how to use AI analytics for businesses.
Data Exploration and Discovery in Data Lakes

Data Exploration and discovery are two critical components of data analysis, allowing businesses to uncover hidden patterns and trends from datasets. Likewise, data lakes are particularly well-suited for these activities due to their flexibility and ability to handle diverse data types.
Hence, here’s how data lakes facilitate effective data exploration and discovery:
- Ad-Hoc Querying Data lakes enable ad-hoc querying, allowing users to run queries on large datasets without the need for predefined data models. Besides, it is essential for exploratory analysis, allowing users to ask specific questions, test hypotheses, and perform data discovery.
- Integration with Data Exploration Tools: It integrates with various data exploration and visualization tools, such as Apache Zeppelin, Jupyter Notebooks, and Tableau. Moreover, these tools provide interactive environments for analyzing and visualizing data, making it easier for analysts to explore datasets.
- Metadata Management and Data Cataloging: Effective data exploration often requires understanding the context and structure of the data. Data lakes can integrate with metadata management and cataloging tools, which provide information about the data’s origin, structure, and quality.
In summary, it provides a robust platform for data exploration with flexible handling and integration with advanced analytics tools. Such abilities make it an invaluable resource for uncovering insights and driving informed decision-making across various industries.
Now, in the following course of our discussion, let’s see how a data warehouse comes par with data lakes.
What is a Data Warehouse?
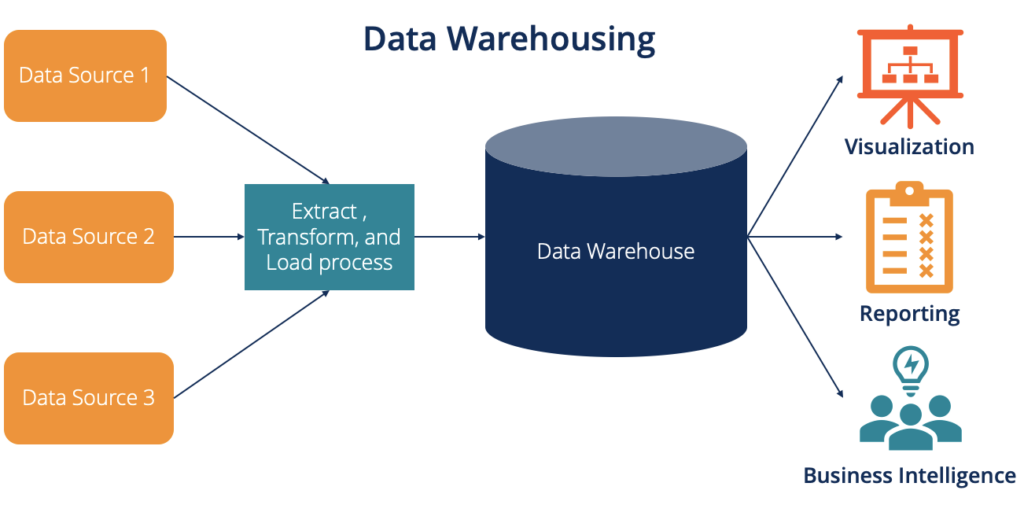
Data warehouses transform into powerhouses for structured data, actively managing and storing vast quantities to fuel efficient querying and analysis. They act as a central hub, consolidating data from diverse sources. Afterwards, this data undergoes a rigorous transformation process, integrating, cleaning, and organizing it all before storage. Also, this meticulous preparation ensures the data is analysis-ready to support business intelligence (BI) initiatives.
Characteristics of Data Warehouses
Accordingly, here are some of the key characteristics of Data Warehouses:
Schema-on-Write
Unlike Data lakes, it utilizes a schema-on-write approach, meaning data must be transformed and structured before loading into the warehouse. Subsequently, it involves defining the schema in advance and organizing the data to fit this schema. As a result, this method ensures that the data is clean, consistent, and optimized for querying. Plus, the predefined schema allows for efficient and reliable data retrieval and analysis.
Storage of Structured Data in an Organized Manner
It stores data in a highly structured and organized manner, typically using a relational database model. Likewise, the data is arranged into tables, columns, and rows, with relationships between the tables being explicitly defined. Consequently, this structured format makes it easy to perform complex queries and analyses.
Optimization for Query Performance
Data warehouses are optimized for read-heavy operations and are designed to handle complex queries efficiently. They employ various techniques to enhance query performance, such as indexing, partitioning, and materialized views. Accordingly, these optimizations enable fast data retrieval and support high-performance analytical workloads, making data warehouses ideal for business intelligence applications.
Use Cases of Data Warehouses
So, as we move towards the conclusion of our analytical debate, it is time we explore some of the extensive use cases of data warehouses for various industries.
With that said, here are some of the primary use cases for data warehouses:
Business Intelligence

The presence of data warehouses are fundamental to business intelligence (BI) systems, providing the foundation for reporting, analytics, and visualization. Afterall, the goal of BI is to support better business decision-making by providing actionable insights from data. Hence, data warehouses play a pivotal role in BI by serving as the central repository for structured data.
Now, let’s examine how:
- Operational Reporting: Data warehouses allow the formation of detailed operational reports that provide insights into day-to-day business activities. These reports help managers monitor performance, track key metrics, and make informed operational decisions.
- Financial Reporting: It supports complex financial reporting requirements, such as profit and loss statements, balance sheets, and cash flow reports. Afterwards, these reports help organizations meet regulatory requirements and make strategic financial decisions.
- Customer Segmentation: By analyzing customer data, businesses can segment their customer base into distinct groups based on demographics, behavior, and other attributes. This helps in developing targeted marketing campaigns and personalized customer experiences.
- Data Consolidation: Businesses can also consolidate data from disparate systems, such as ERP, CRM, and external data sources, into a single repository.
Consequently, this consolidation simplifies data management, with a proper ERP implementation, businesses can access accurate and updated informations.
Additionally, you may reach out to our ERP experts to know more on it.
Reporting and Dashboarding

Data warehouses allow businesses to generate comprehensive reports and interactive dashboards that offer insights into various aspects of the business. These two are very vital as they provide businesses the ability to visualize, analyze, and interpret their data.
So, let’s get a detailed look at how data warehouses support reporting and dashboarding:
- Operational Reports: It supports operational reporting, providing insights into daily business activities. Likewise, reports can cover areas like sales performance, inventory levels, production metrics, and customer service metrics.
- Customization and Flexibility: Users can customize dashboards to display the metrics that are most relevant to their roles and responsibilities. Moreover, this flexibility ensures that each user has access to the information they need to make informed decisions.
- Drill-Down Capabilities: Dashboards often include drill-down capabilities, allowing users to explore data in greater detail. Hence, by clicking on a metric, users can access underlying data and perform more in-depth analysis.
- Increased Efficiency: Automated reporting and real-time dashboards reduce the time and effort required to gather and analyze data. As a result, it increases efficiency and allows employees to focus on higher-value tasks.
In brief, these capabilities enhance decision-making, improve visibility, increase efficiency, and facilitate collaboration across businesses. In today’s data-driven business environment, the ability to generate accurate and timely reports and dashboards is critical for thriving businesses.
Historical Data Analysis

Notably, data warehouses are designed to store vast amounts of historical data, making them ideal for longitudinal analysis. As a result, businesses can track changes and trends over time, getting a deeper understanding of performances and market dynamics.
So, let’s get an in-depth look at how data warehouses support historical data analysis:
- Extended Data Retention: It retains data for many years, ensuring that historical information is preserved and accessible for analysis. Subsequently, this long-term storage is essential for businesses that need to analyze data trends over multiple years or decades.
- Consistent Data Quality: Enforces data quality standards through ETL (extract, transform, load) processes, ensuring that historical data is accurate, consistent, and reliable. Eventually, this consistency is crucial for meaningful historical analysis.
- Demand Forecasting: With the use of historical sales data, businesses can forecast future demand for products, to optimize inventory and reduce stockouts. In addition, accurate demand forecasting improves customer satisfaction and reduces carrying costs.
- Regulatory Compliance: Businesses can utilize historical data analysis to ensure compliance with regulatory requirements, such as Basel III and IFRS. As, historical data helps in verifying adherence to regulations and supports audit processes.
All in all, it serves as a powerful use case for data warehouses, allowing to unlock valuable insights from past data.
Data Lake Vs Data Warehouse: Key Differences
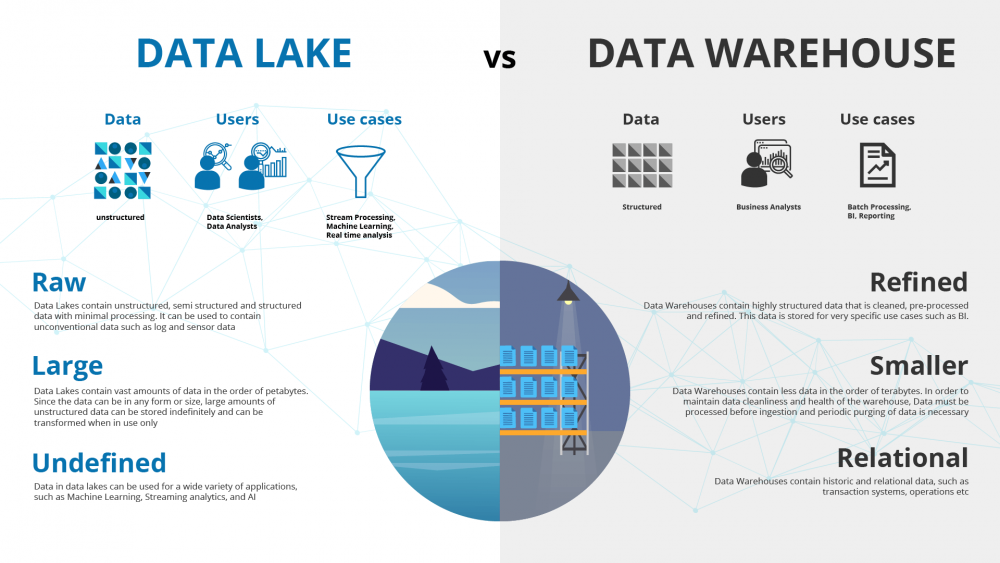
Now, coming to the most awaited part of our competitive analysis of data lake vs data warehouse. Let’s understand how these data management solutions help businesses determine the best fit for their needs.
As mentioned earlier, these two are distinct approaches to storing and managing data, each with its own set of characteristics. Hence, a full comprehension of its key differences is highly crucial for businesses.
Data Structure: Unstructured vs. Structured Data
A data lake can store raw data in its native format, including structured, semi-structured, and unstructured data. This includes everything from databases and spreadsheets to images, videos, and social media feeds. Plus, the flexibility of data lakes makes them ideal for handling diverse data types without requiring any predefined schema.
In contrast, a data warehouse actively stores highly structured data, already processed and meticulously organized. Before loading, the data undergoes a rigorous cleaning, transformation, and formatting process to comply with a predefined schema. This structured approach empowers the data warehouse to deliver efficient querying and reporting capabilities.
Schema Approach: Schema-on-Read vs. Schema-on-Write
Data lakes employ a schema-on-read approach, meaning the data schema is applied at the time of reading or querying the data. Likewise, it allows for greater flexibility, as data can be ingested in its raw form and later structured as needed for different types of analysis.
Whereas, data warehouses use a schema-on-write approach, where data is structured and organized according to a predefined schema before loading. Consequently, it ensures data consistency and optimization for query performance but requires a well-defined schema upfront.
Cost and Scalability: Differences in Storage and Compute Costs, Scalability Aspects
Typically, data lakes are built on cost-effective storage solutions, such as cloud-based storage platforms, scaling horizontally to handle large data. Also, the separation of storage and compute in data lakes allows for flexible scaling of resources based on demand.
On the other hand, data warehouses often rely on more expensive storage solutions optimized for performance. As, they are designed for high-speed queries and complex analytics, which can result in higher storage and compute costs.
Performance: Query Performance and Data Retrieval Times
Data lakes excel at storing massive amounts of varied data, but complex queries, especially on unstructured or semi-structured data, can be slow. However, integrating data processing with advanced frameworks can significantly improve query performance.
On the other hand, data warehouses are specifically designed for fast querying and efficient data retrieval.
Also, they can handle complex queries on structured data, making them ideal for business intelligence and reporting applications.
Data Governance and Security
Data governance and security in data lakes can be more complex due to the diverse types of data. Hence, implementing robust data governance policies, access controls, and security measures is essential to ensure data integrity and compliance.
Nonetheless, data warehouses have well-established data governance and security frameworks, due to their structured nature and predefined schemas. They typically include features for data auditing, lineage tracking, access control, and compliance with regulatory requirements.
Choosing the Right Solution for Your Business (Data lake vs Data warehouse)
Most importantly, as we clearly covered the distinct differences between the two data management practices – In context, to (data lake vs data warehouses) its time to determine, which is the right solution for your business.
Assessing Business Needs
With that said, let’s see some of the following factors to make an informed decision:
- Volume and Variety of Data: If your business handles large volumes of diverse data types, a data lake may be more suitable. However, if you primarily work with structured data and require fast query performance, a data warehouse is a better choice.
- Types of Analytics and Reporting Required: For businesses that need to perform big data analytics, machine learning, and exploratory data analysis, a data lake is advantageous. But, If your business relies heavily on business intelligence, reporting, and historical data analysis, a data warehouse is more appropriate.
- Speed and Performance Needs: Data lakes offer scalability and flexibility but may have slower query performance, especially with large volumes of unstructured data. But for scenarios where speed and performance are paramount, such as real-time reporting and dashboarding, a data warehouse is ideal.
So, while opting over a data lake vs data warehouse – Consider choosing the right data management solution based on careful evaluation of your specific needs, data characteristics, and analytical requirements.
Hybrid Approaches
Eventually, combining data lakes and data warehouses provide a comprehensive solution that leverages the strengths of both approaches.
Let’s have a look how:
Data lake vs Data warehouse: A combination
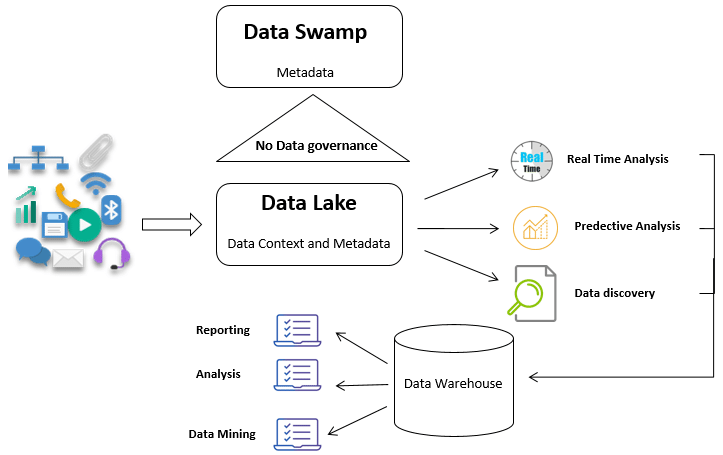
Use a data lake to store raw, unstructured, and semi-structured data. Consequently, it allows for flexible data ingestion and the ability to perform a wide range of data processing and analysis.
Whereas, use a data warehouse to store processed, structured data that requires efficient querying and reporting. So, it ensures high performance for business intelligence and analytics tasks.
Benefits of a Hybrid Data Architecture
Now, here are some benefits of the benefits of hybrid data architecture:
- Scalability and Flexibility: A hybrid approach offers the scalability and cost-effectiveness of data lakes for raw data storage and processing. Alongside, it elevates the performance and reliability of data warehouses for structured data analytics.
- Optimized Resource Utilization: By leveraging the strengths of both data lakes and data warehouses, businesses optimize resource utilization and meet diverse data requirements. As a result, it ensures that data is stored and processed in the most efficient and cost-effective manner.
- Enhanced Analytics Capabilities: Plus, a hybrid architecture supports a wide range of analytics capabilities, from big data processing and machine learning algorithms.
Overall, such capabilities provide a comprehensive analytical platform that addresses various use cases across industries.
Case Studies
Now, having explored all the angles of our discussion on a data lake vs data warehouse – Let’s delve deeper with its practical case studies across industries. So, here we go:
Examples of Companies Using Data Lakes
Netflix uses a data lake to store and process vast amounts of diverse data. It enables them to leverage advanced analytics and machine learning algorithms to personalize content recommendations and improve user experience.
Uber too leverages a data lake to manage data from various sources, supporting real-time analytics and improving operational efficiency. Also, data lake allows Uber to handle large volumes of data generated by its platform.
Examples of Companies Using Data Warehouses
Amazon employs a data warehouse to power its business intelligence and reporting capabilities. Also, the data warehouse enables efficient analysis of sales, inventory, and customer data, supporting strategic decision-making.
Accordingly, Walmart too uses a data warehouse to manage and analyze vast amounts of transactional data. Additionally, it supports business decisions and optimizes supply chain operations by providing fast and reliable access to structured data.
Examples of Companies Using a Hybrid Approach
GE utilizes a hybrid data architecture, combining data lakes for IoT-Data processing with data warehouses for business intelligence and reporting. Consequently, this approach allows GE to manage a wide range of data types and analytical requirements.
Airbnb also adopts a hybrid approach to manage diverse data types, leveraging the scalability of data lakes. As a result, it allows Airbnb to support advanced analytics and gain operational insights, enhancing its data strategy.
Undoubtedly, this approach brings a win-win scenario in context to data lake vs data warehouse choices.
How TheCodeWork can help you?

So, for businesses who are trying to navigate through modern data management, TheCodeWork can stand out as a key partner. Eventually, understanding the differences between a data lake vs data warehouse is crucial, and TheCodeWork excels in guiding through this.
We assist businesses by implementing scalable data lake and warehouse solutions that facilitate efficient data ingestion, storage, and retrieval. Also, our team actively streamlines your data solutions for seamless data integration, transformation, and analysis.
By leveraging TheCodeWork’s expertise, businesses can effectively navigate the data lake vs data warehouse debate. With our expertise, businesses can confidently choose the best data management solution, aligned with their goals. For any inquiries on data solutions, Contact Us for personalized guidance and the best-in-class management solutions.
Bottom Line
Summing Up, as we came to an end of our debate on data lake vs data warehouse – The choice largely depends on the business requirements, based on careful assessments of data volume, variety, and analytical needs.
By making a well-informed choice, businesses can effectively optimize their data strategy. This optimization not only enhances data management processes but also empowers organizations to derive actionable insights and make strategic decisions. Therefore, choosing the right data management solution is instrumental in driving a business, maintaining a competitive edge in today’s landscape.
FAQs
Q1: When should a business choose a data lake over a data warehouse?
Ans: A business should consider a data lake when it needs to handle large volumes of diverse data types, including unstructured datas. Moreover, data lakes are ideal for scenarios involving big data analytics, real-time processing, and machine learning.
Q2: What are the advantages of using a Data Warehouse?
Ans: A data warehouse offers several advantages for businesses, including:
- Structured Data Storage: It organizes data into a structured format, making it easy to query and analyze.
- Optimized Performance: Data warehouses are designed for high-performance querying and reporting, enabling fast data retrieval and complex analytics.
In addition, it ensures data consistency and accuracy, which is crucial for reliable business intelligence and decision-making.
Q3: Can a business use both a data lake and a data warehouse?
Ans: Yes, many businesses utilize both a data lake and a data warehouse to leverage their respective strengths. This hybrid approach allows businesses to store and analyze raw, unstructured data in the data lake. Whereas, using the data warehouse for structured, high-performance analytics and reporting.
Q4: How do data lakes and data warehouses impact data security and governance?
Ans: Data lakes and data warehouses have different implications for data security and governance. Subsequently, data lakes often store raw, unstructured data, which can pose challenges for maintaining consistent security and governance policies. However, modern data solutions incorporate advanced security features like encryption and access controls to protect sensitive data.