So before we begin, allow us to deliver a quick review of Scrapy Python.
Scrapy is a web crawler framework which is written using Python coding basics. It is an open-source Python library under BSD License(So you are free to use it commercially under the BSD license).
Scrapy was initially developed for web scraping. It can be operated as a broad spectrum web crawler. Scrapy also serves the purpose of collecting data using BeautifulSoup APIs, xpaths, css etc.
This article will give you a step by step Scrapy tutorial to building your web scraping tool to collect data from a list of items. This will also help you dig further into multiple links to get information connected to a second page using the Python coding basics and scrapy.
Before proceeding, the primary thing to remember while using scrapy or any other crawler tool to create your bot is to comply with crawling rules given by the websites. To do so, you can find the rules in *website*/robots.txt in general.
Scrapy provides with a sweet little setting that would do the same thing and crawl through the allowed domains if made ROBOTSTXT_OBEY to True.
Installation & Setup
I like the information old school to provide wholesomely while using Python coding ideas. If you have already set up your project, you can skip over to our next section “Setting up Items”.
Create a project and set up a virtual environment using python virtual environment package.
Once you are inside the environment, create a scrapy project.
We are going to take the example from Scrapy’s tutorial with “http://quotes.toscrape.com”.
On top of that, we’ll move to the next page to collect the information of the Author that is available for each quote.
We’ll call the project quotes and create it with
scrapy startproject tutorialThis command will create a base set of files for the project for you.
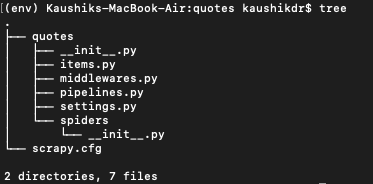
- items.py – Would contain the data model you are trying to capture for each record.
- pipeline.py – Takes each item (or record) and processes as per your requirements. You essentially validate, set export parameters over here.
- middlewares.py– Would contain any custom middleware you want to include in addition to the default middlewares provided by the framework. You can write your custom middleware for proxy setup as well.
- settings.py– Would control the project and all your settings are essentially present in this file.
- spiders – Would contain all the spider (crawler) you create and would contain the main file you run your scrapy for.
Setting up Items
The first thing to set up after you have created a scrapy project is your item file. Take a look at the site you are about to crawl and note all the data points that you would need that are available in a structured manner.
Going by our quotes website, let’s settle this up with the following:
- quote
- author
- tags
- born_information
- author_description
Use them to define the default Scrapy Field.
Setting up the Pipeline
We will use the pipeline to export our file in CSV.
We will create a custom pipeline inheriting from the CsvItemExporter available from scrapy.exporters .
The code below will set up a CSV exporter.
Once you have setup the pipelines, add these inside settings.py that has been used in the pipelines.py file.
Setting up the spider
Create your main crawling file (e.g., qoutes_spider.py) inside the “spiders” directory.
When we run our spider the python code would initially set up the spider according to the initialization and other middlewares before making an http request.
The important thing to note here is once your response is returned, the default callback URL is defined in scrapy is “parse”. We will be utilizing both the default as well as our custom callback.
We’ll be inheriting the spider from the CrawlSpider modules of scrapy to iteratively travel through the collected allowed URLs.
The use of scrapy shell comes quite handy over here to essentially find and check the xPath collected from the developers tool of the browser and use it for your codebase.
We’ll set up our codebase with 4 important tweaks/feature over here:
- Inherit it from CrawlSpider and setup rules by utilizing the LinkExtractor.
- Create a clean_url method to always feed the correct URL to the Requests.
- We’ll create a custom parse method to get the data of the author’s description and birth information(born_information) from the connected page.
- We’ll capture all the failed URLs to inspect later on in case of a network or Timeout error.
Code Explanation
At this point, it is very wise to invoke the shell from scrapy and have a look at all the elements to verify the xPath and data that you are looking for. Use this command to make request to the page listed below with scrapy shell
scrapy shell http://quotes.toscrape.com/page/1/
If you are getting ‘FileNotFoundError’ get inside your quotes directory.
Head over to your browser to get the xPath syntax of the required data and check it out on the shell.
The xPath for the quotes at the time of writing this blog is represented by:
/html/body/div/div[2]/div[1]/div[1]/span[1]/text()
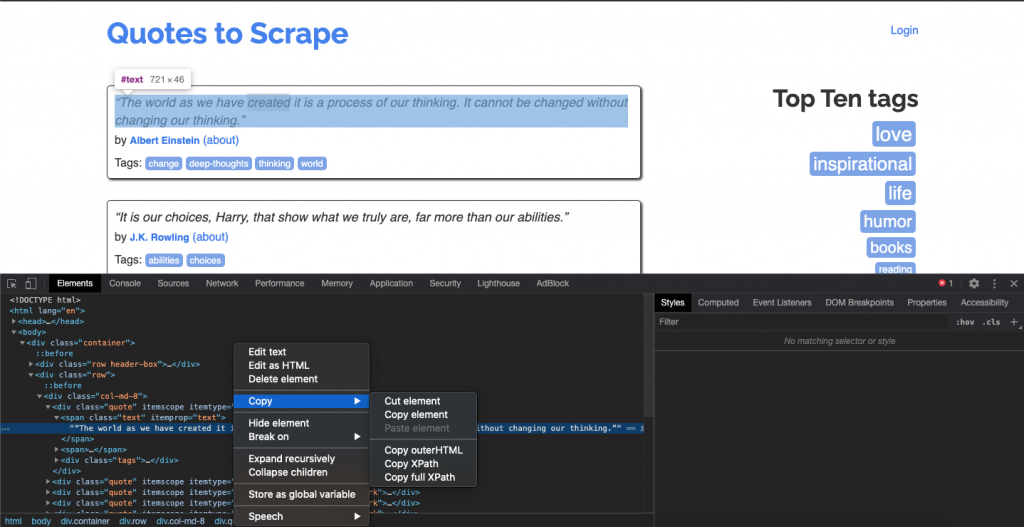
If we try this in our shell it will give out the data we need.

Now, this will give you only a single record from the page but your page contains a list of quotes. We need to find the div element (<tr> in case of a table) to get all the data. The below given xPath will give you the list. Try this out in the shell and checkout the results you are getting. With a little effort, you’ll understand how the results are changing by changing the xPath.
/html/body/div/div[2]/div[1]/div
We’ll use this in our codebase to get all the quotes from a single page.
We’ll iterate over them and get a relative xPath to fetch the respective data from this page. e.g., to get the quotes, we can get it from
“.//span[1]/text()”
Similarly, we’ll also fetch the author and tags.
Once we get the author URL, we’ll clean it and then send it to another parse, callback (parse_author_detail_page) to get the data needed for the born_information and the author_description from the second page.
Please note that the callback to this is still a synchronous process so the current item will only be processed once we yield in the parse method.
To handle the errors during network issues we’ll implement an error handler that will append to a list for each failed attempt. This error list (failed_url) will be finally put into a CSV file on the closed signal of the crawler.
Running the spider with a state
You can start running your codebase with
scrapy crawl quote bot.It will immediately start running your spider, but you cannot pause it in between. To do so, run the crawler with a state. Use the state in the codebase from the CrawlSpider and run the following:
scrapy crawl quote bot -s JOBDIR=crawls/quotespider-1
This will start the crawler and feed your data and export them into the CSV files generated inside your io_files.
You can find the entire codebase over at:
https://github.com/kaushikdr/scrapy_quote_tutorial
P.S: The proxy code is added in the middleware but is disabled in the settings. If you need to add it, you can enable the DOWNLOADER_MIDDLEWARES. There are various measures you can use to avoid being blacklisted. Maintain your bot to shadow a human behavior as close as possible by reducing the concurrency and adding a delay to your spider.
Overview
We at TheCodeWork believe startups can change the world for the better with their unique ideas. We venture ourselves from FullStack Development to Mobile Development to scripting and beyond using Python, PHP, javascript and many other languages and their frameworks. If you need any help to build your scripting tool or have any startup idea, contact us at TheCodeWork and we would love to brainstorm on your idea.